Phase 1: 数据加载与转换
状态: ✅ 已完成 时间: 2025-12-26 目标: 正确加载和解析三模态数据
为什么这一步很重要?
在开始分析之前,我们必须先能读取数据。
听起来简单,但实际上:
- .mat 文件(MATLAB 格式)结构复杂
- 数据嵌套了 3 层
- 有大量 NaN (缺失值)需要处理
如果这一步失败,后面什么都做不了!
遇到的第一个问题
初始尝试
我们写了第一版加载脚本,运行后:
📹 Vision: ❌ not found
📱 IMU: ❌ not found
💪 EMG: ❌ not found全部失败! 😱
排查问题
我们创建了 explore_mat_structure.py 来探索文件结构:
python
def explore_nested_dict(obj, indent=0):
"""递归探索嵌套结构"""
if isinstance(obj, dict):
for key in obj.keys():
print(" " * indent + f"📁 {key}:")
explore_nested_dict(obj[key], indent + 1)
elif isinstance(obj, np.ndarray):
print(" " * indent + f"📊 Array shape: {obj.shape}")发现数据藏在这里:
Datastr (根节点)
└─ [0, 0] (索引)
├─ IMU
│ └─ [0, 0]
│ ├─ IMUData ← 真正的数据!
│ └─ IMUFrameRate
├─ EMG
│ └─ [0, 0]
│ ├─ Channels ← 真正的数据!
│ └─ FrameRate
└─ Marker
└─ [0, 0]
├─ MarkerData ← 真正的数据!
└─ FrameRate原来要这样访问:
python
# ❌ 错误
data = mat_data['IMU']
# ✅ 正确
datastr = mat_data['Datastr'][0, 0]
imu_struct = datastr['IMU'][0, 0]
imu_data = imu_struct['IMUData']嵌套了 3 层!
正确的加载方法
完整代码
python
from scipy.io import loadmat
def load_multimodal_data(mat_path):
"""加载三模态数据"""
# 1. 加载 .mat 文件
mat_data = loadmat(mat_path)
# 2. 进入第一层
datastr = mat_data['Datastr'][0, 0]
# 3. 提取 IMU
imu_struct = datastr['IMU'][0, 0]
imu_data = imu_struct['IMUData'] # (samples, 29)
imu_rate = int(imu_struct['IMUFrameRate'][0, 0])
# 4. 提取 EMG
emg_struct = datastr['EMG'][0, 0]
emg_data = emg_struct['Channels'] # (samples, 9)
emg_rate = int(emg_struct['FrameRate'][0, 0])
# 5. 提取 Marker
marker_struct = datastr['Marker'][0, 0]
marker_data = marker_struct['MarkerData'] # (33, 3, samples)
marker_rate = int(marker_struct['FrameRate'][0, 0])
return {
'imu': {'data': imu_data, 'rate': imu_rate},
'emg': {'data': emg_data, 'rate': emg_rate},
'marker': {'data': marker_data, 'rate': marker_rate}
}成功!
再次运行,这次成功了:
✅ IMU Data: 240 Hz, shape (8956, 29), duration 37.3s
✅ EMG Data: 2048 Hz, shape (76480, 9), duration 37.3s
✅ Marker Data: 128 Hz, shape (33, 3, 4780), duration 37.3s数据规格详解
IMU 数据
python
shape: (8956, 29)
↑ ↑
| └─ 29 个特征
└─ 8956 个采样点
采样率: 240 Hz
时长: 8956 / 240 = 37.3 秒
29 个特征包括:
- 前 3 列: 陀螺仪 (gyro_x, gyro_y, gyro_z)
- 接下来 3 列: 加速度计 (acc_x, acc_y, acc_z)
- 其他: 磁力计、姿态角等EMG 数据
python
shape: (76480, 9)
↑ ↑
| └─ 9 个肌肉通道
└─ 76480 个采样点
采样率: 2048 Hz (非常高!)
时长: 76480 / 2048 = 37.3 秒
9 个通道:
- 通道 0-2: 腿部肌肉 (推测)
- 通道 3-5: 核心肌肉 (推测)
- 通道 6-8: 手臂肌肉 (推测)Marker 数据
python
shape: (33, 3, 4780)
↑ ↑ ↑
| | └─ 4780 个时间帧
| └─ 3 个坐标 (X, Y, Z)
└─ 33 个身体标记点
采样率: 128 Hz
时长: 4780 / 128 = 37.3 秒
33 个标记点包括:
- 头部、肩膀、手肘、手腕
- 髋部、膝盖、脚踝
- 等等...可视化验证
我们创建了 visualize_kinetic_emg.py 来可视化所有三种模态:
结果图
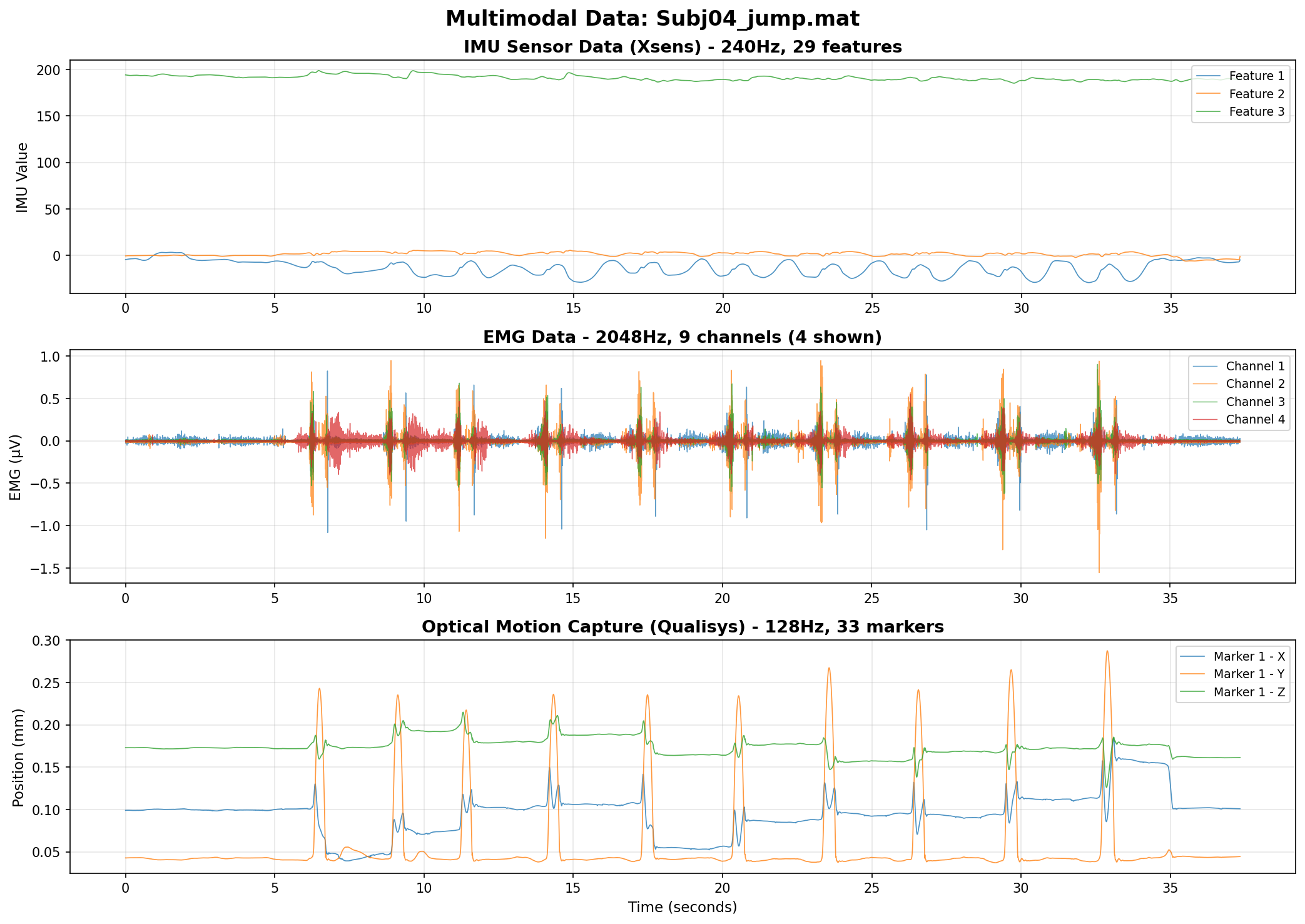
图中显示:
- EMG (上): 9 个通道的肌肉激活
- Marker (中): 33 个标记点的 Z 坐标(高度)
- IMU (下): 陀螺仪和加速度计
所有数据完美同步! ✅
处理缺失值
Marker 数据有很多 NaN (缺失值):
Total markers: 33 × 3 × 4780 = 473,580 个值
NaN count: 1,728 个 (约 0.36%)为什么有 NaN?
光学动捕系统有时会"丢失"某个标记点:
- 被身体其他部位遮挡
- 反光球脱落
- 摄像头角度不好
如何处理?
python
# 使用 nanmean 而不是 mean
com = np.nanmean(marker_data, axis=0)
# 插值填充
valid_mask = ~np.isnan(z_position)
z_position = np.interp(
np.arange(len(z_position)),
np.where(valid_mask)[0],
z_position[valid_mask]
)时间同步验证
三个传感器的数据时长:
IMU: 8956 / 240 = 37.31666... 秒
EMG: 76480 / 2048 = 37.34375 秒
Marker: 4780 / 128 = 37.34375 秒差异 < 30ms,非常好!
这说明数据集本身就是高质量的,时间同步做得很好。
代码文件
所有代码在:
scripts/explore_mat_structure.pyscripts/load_kinetic_emg_dataset.pyscripts/visualize_kinetic_emg.py
经验总结
教训 1: 不要假设数据结构
一开始我们假设数据在顶层,但实际上嵌套了 3 层。
经验: 先探索结构,再写加载代码。
教训 2: 处理 NaN
真实数据总是有缺失值,必须处理。
经验: 使用 nanmean, nanmax 等函数,或者插值填充。
教训 3: 验证时间同步
不能假设数据已经同步,必须验证。
经验: 计算每个模态的实际时长,确认一致性。
下一步
Phase 1 完成,数据加载没问题! ✅
现在可以进入 Phase 2: 特征提取,开始提取 12 个核心指标。